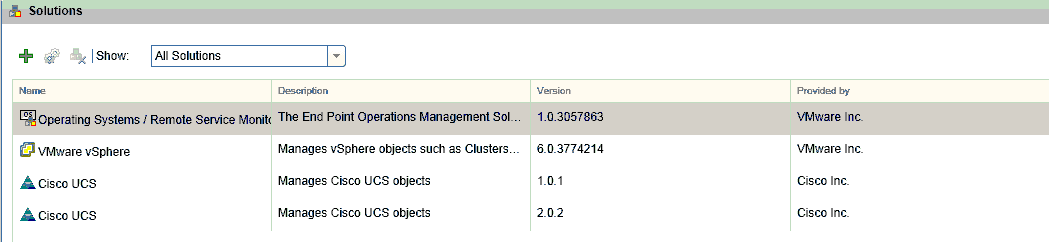
The great thing about having a lab environment is I get to test out a number of solutions for vROps. One that I have been evaluating is the Cisco UCS Management Pack for vROps. We started with a beta version for vROps 5.x then updated the pack for vROps 6.1 and now I wanted to install the newest version of the pack for 6.2. One problem, the old solutions are just kinda stuck in there. They don’t update and when you think you are removing the solution, you are really just deleting the adapter settings. In this article ill go through the steps on how to remove the old management packs and get everything clean and ready for the new version.

***Caution!*** – we are going to be editing some sensitive files so you really should open up a service request with VMware support if you are doing this in production. I’m working in my lab environment so if things went FUBAR, its not a big deal. I will have to eventually do this in production, (well not me, the operations team) and so far I haven’t had any issues going through this, but ya never know. Open up an SR before touching your production vROps. This way in an event of an issue or a mistake VMware support can help guide you through fixing it. Okay, enough of that.
The fist step is to log into the vROps node that has the incompatible solution. In my lab I only have one node, so that’s pretty straight forward.
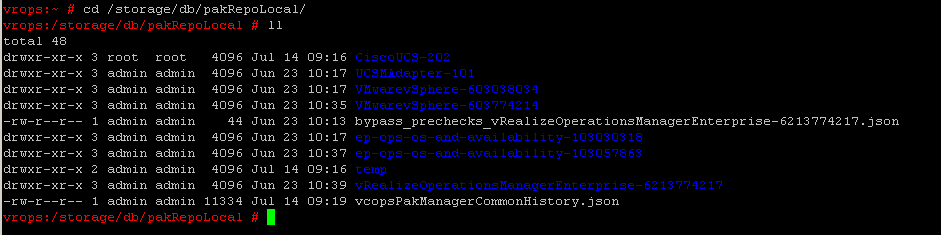
navigate to /storage/db/pakRepoLocal/ to determine which solution you want to uninstall. I have a couple different UCS solutions installed.

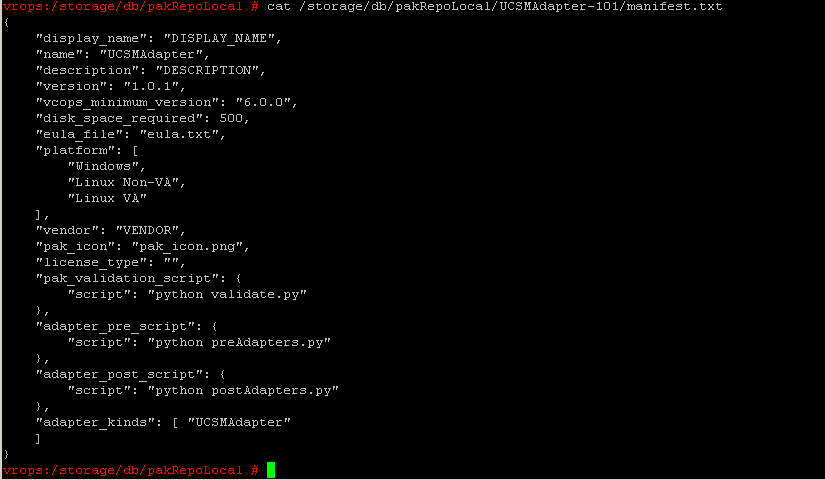
Run this command to determine the actual adapter name and take note of the “Name” field.
cat /storage/db/pakRepoLocal/Adapter_Folder/manifest.txt

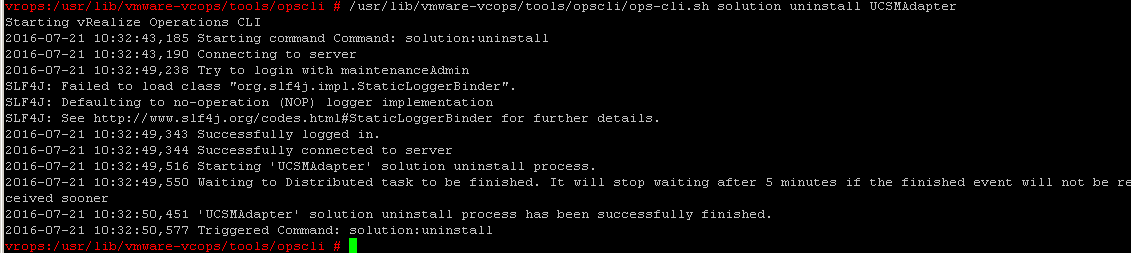
The next step to uninstall the solution pack is to change to /usr/lib/vmwarevcops/tools/opscli/ and run the opscli.sh with the uninstall option
./opscli.sh solution uninstall “Name_of_the_pak”
Once the process has completed you will see a return that states the uninstall has been successful. Like in the example below.

After the above step is complete, run this for some additional clean up.
$VMWARE_PYTHON_BIN $ALIVE_BASE/../vmwarevcopssuite/utilities/pakManager/bin/vcopsPakManager.py –action
cleanup –remove_pak –pak Name_of_Pak (replace Name_of_Pak with the name from above)

Next you will have to remove the solutions .pak file from the .pak files directory.
Go to $STORAGE/db/casa/pak/dist_pak_files/VA_LINUX and rm the pack file name.

Now open /storage/db/pakRepoLocal/vcopsPakManagerCommonHistory.json in a text editor and delete all entries related to the removed solution from { to } Don’t forget to save it!

Lastly go back to the /storage/db/pakRepoLocal/ directory and remove the sub directories, files and parent directory for the solution you removed. Use the rm and rmdir commands. You may also have to delete any dashboards that were installed with the solutions pack from dashboards in the vRealize Operations Manager UI. Also note that in order for the changes to take effect, you will need to log out and back into the UI.
Take your time running through the steps and you will see its not all that difficult. I’ve also used this process when a solution doesn’t install successfully before I try and reinstall it and remember to take caution when doing this in a production environment.